



MoCha: l'AI per il cinema

Meta ha recentemente presentato MoCha, un modello AI sviluppato in collaborazione con l'Università di Waterloo in grado di generare personaggi animati che parlano e si muovono in modo naturale.
Esistono numerosi sistemi capaci di produrre video o sintetizzare audio separatamente, ma solo pochi riescono a fare bene entrambe le cose. MoCha combina le due capacità in un unico modello, generando personaggi "parlanti", con espressioni facciali e movimenti delle mani piuttosto fluidi e realistici.
MoCha è stato presentato al pubblico attraverso questo video e questo paper su arxiv (qui riassunto).
Caratteristiche principali di MoCha
 Fonte: MoCha
Fonte: MoChaMoCha si distingue dai classici sistemi di generazione "talking head" grazie a una serie di innovazioni tecniche che permettono una qualità cinematografica decisamente migliore.
Generazione End-to-End di Personaggi Parlanti
- Produce animazioni a corpo intero, non solo espressioni facciali, sincronizzate con il parlato
- Supporta vari tipi di inquadratura (primi piani, medi, ampi) e stili di personaggi (umani, cartoni animati, animali)
- Genera video HD di circa 5 secondi a 24 fotogrammi al secondo
Flessibilità di Input
- Prompt: Definisce personaggi, scene, azioni e inquadrature
- Audio vocale: Guida i movimenti delle labbra, le espressioni facciali e i gesti corporei
Specifiche Tecniche
- Modello: Diffusion Transformer con 30 miliardi di parametri
- Risoluzione output: 720p
- Durata clip: 5,3 secondi (128 fotogrammi a 24 FPS)
- Benchmark: MoCha-Bench con 150 casi di test
Innovazioni Tecniche
- Speech-Video Window Attention: Un meccanismo di attenzione che allinea i token vocali con i fotogrammi video, garantendo una sincronizzazione labiale precisa e movimenti naturali
- Strategia di formazione congiunta: Integra dati video con etichette vocali (ST2V) e dati video solo testuali (T2V) per migliorare la generalizzazione
- Conversazioni multi-personaggio: È il primo modello a supportare dialoghi strutturati a turni tra più personaggi utilizzando prompt con tag di personaggio
Puoi visualizzare i contenuti generati da MoCha qui.
Come Funziona MoCha: Architettura e Formazione
MoCha è basato su un'architettura Diffusion Transformer (DiT) che processa token video latenti. Il sistema condiziona la generazione video su incorporamenti vocali (utilizzando Wav2Vec2) e input di testo.
Il processo di formazione utilizza Flow Matching per una simulazione efficiente della dinamica e segue un approccio multi-stadio:
- Inizia con primi piani (forte correlazione vocale)
- Introduce gradualmente attività più complesse, come il movimento a corpo intero
Per addestrare il sistema, i ricercatori hanno utilizzato 300 ore di contenuti video attentamente filtrati, anche se non hanno rivelato la fonte del materiale. Questo dataset è stato integrato con sequenze video basate su testo per espandere la gamma di espressioni e interazioni possibili.
Superare le Sfide della Sincronizzazione Labiale
MoCha risolve due sfide persistenti nella generazione video AI:
- La compressione video durante l'elaborazione mentre l'audio rimane a piena risoluzione
- I movimenti labiali non corrispondenti durante la generazione video parallela
Il sistema ottiene questo risultato limitando l'accesso di ciascun fotogramma a una finestra specifica di dati audio. Questo approccio riflette il funzionamento del parlato umano: i movimenti labiali dipendono dai suoni immediati, mentre il linguaggio del corpo segue modelli più ampi nel testo.
Gestione di più personaggi
Una delle caratteristiche più innovative di MoCha è la capacità di gestire scene con più personaggi, per la quale il team ha sviluppato un sistema di prompt semplificato:
- Gli utenti possono definire i personaggi una sola volta
- È possibile fare riferimento ai personaggi con semplici tag come 'Person1' o 'Person2' in scene diverse
- Non è necessario ripetere descrizioni dettagliate
Nei test su 150 scenari diversi, MoCha ha superato sistemi simili sia nella sincronizzazione labiale che nella qualità dei movimenti naturali. Valutatori indipendenti hanno giudicato i video generati come realistici. Nonostante ciò, gli utenti di Reddit ammettono che alcune espressioni facciali o vocali dei personaggi risultano ancora irrealistiche o esagerate.
MoCha vs Altri Sistemi di Generazione Video AI
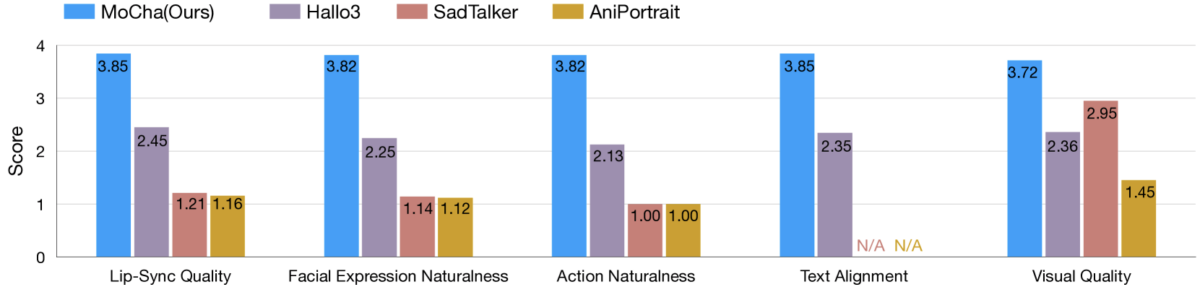 Fonte: paper su arxiv.org
Fonte: paper su arxiv.orgMoCha si distingue da altri sistemi AI come SadTalker, AniPortrait e Hallo3 sotto diversi aspetti:
- Elimina la dipendenza da input ausiliari (es. immagini di riferimento)
- Abilita interazioni tra più personaggi - una novità nel settore
- Raggiunge un realismo cinematografico attraverso strategie avanzate di allineamento e formazione
Applicazioni e futuro di MoCha
Secondo il team di ricerca, MoCha mostra potenziale per una vasta gamma di applicazioni:
- Assistenti digitali e avatar virtuali
- Pubblicità e contenuti educativi
- Creazione di personaggi per l'industria cinematografica
- Influencer virtuali
- Narrazione interattiva
Lo sviluppo di MoCha è particolarmente significativo nel contesto della corsa delle principali aziende di social media per avanzare la tecnologia video basata sull'AI. Meta ha recentemente lanciato MovieGen, mentre ByteDance (la società madre di TikTok) sta sviluppando una propria suite di sistemi di animazione AI, tra cui INFP, OmniHuman-1 e Goku.
"Che si tratti di film, influencer virtuali o narrazione interattiva, MoCha apre la strada a un futuro in cui i personaggi generati dall'AI sono indistinguibili dagli attori reali."
Verso film completamente generati dall'AI?
Con l'evoluzione continua dell'AI, è solo questione di tempo prima che strumenti come MoCha diventino parte integrante dell'industria creativa. La domanda sorge spontanea: l'AI dirigerà presto interi film?
Fonti:
Wei et al su Arxiv
Medium
