



TUTTO ciò che devi sapere su GPT 4.5

OpenAI ha lanciato GPT-4.5, presentandolo in un lungo articolo sul suo blog. In questo articolo riassumeremo le informazioni più importanti per capire i punti di forza e di debolezza del modello, le reazioni degli esperti e la posizione rispetto ai competitor.
Attualmente in research preview (una fase di test per raccogliere feedback dagli utenti), GPT-4.5 è disponibile per gli utenti Pro, e verrà esteso agli altri piani gradualmente nelle prossime settimane.
✅ Punti chiave e miglioramenti principali:
- Maggiore "EQ" (intelligenza emotiva) per conversazioni più naturali.
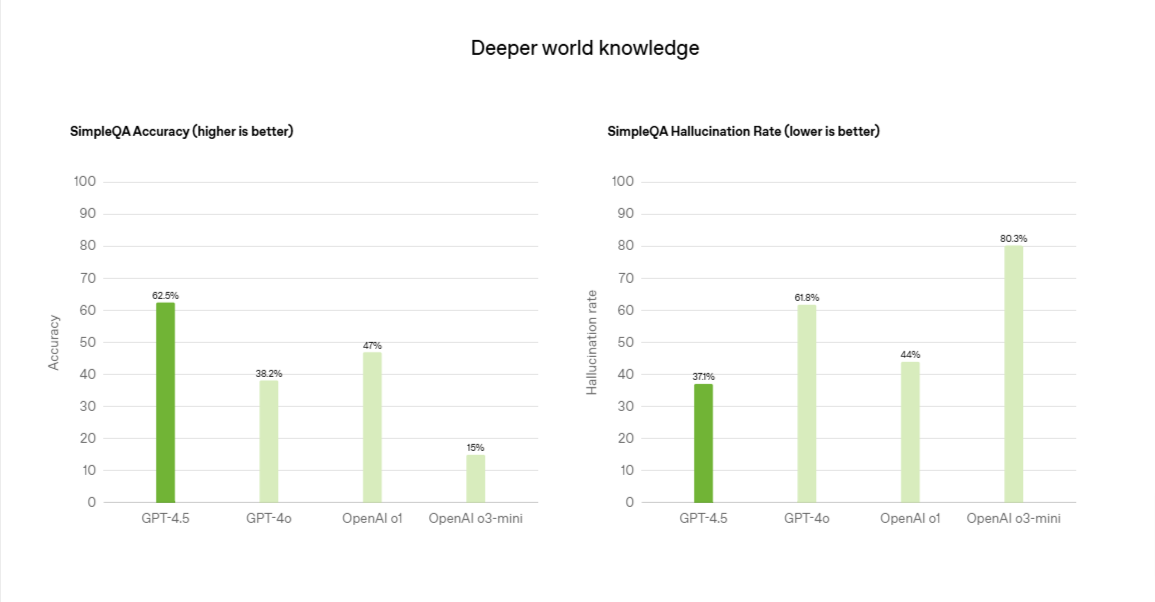
- Meno allucinazioni: riduzione dal 61.8% (GPT-4o) al 37.1%.
- Migliore accuratezza nei test di conoscenza (62.5% nel test SimpleQA, vs 38.2% di GPT-4o).
- Più efficiente dal punto di vista computazionale, ma ancora molto costoso.
✅ Limiti e criticità:
- Non è un modello di frontiera: miglioramenti diffusi ma nessuna innovazione rivoluzionaria.
- Prezzo elevato, fino a 25 volte più costoso rispetto ai competitor.
- Non è un modello di ragionamento (né totale né ibrido).
- Non eccelle nella programmazione, a differenza di Grok 3 e Claude 3.7
✅ Disponibilità e futuro:
- Disponibile in ChatGPT Pro e in anteprima nell’API.
- Non supporta ancora Voice Mode, video e screen sharing.
- OpenAI sta valutando se mantenerlo a lungo termine, dato il costo elevato.
📌 GPT-4.5 è un modello più naturale, creativo e affidabile, ma non una rivoluzione.
OpenAI, GPT-4.5 e l'apprendimento non supervisionato
OpenAI ha rilasciato una versione di anteprima di GPT-4.5, definita sul blog come "il modello più grande e migliore per la chat fino ad oggi". Secondo OpenAI, interagire con GPT-4.5 risulta più naturale grazie a una base di conoscenze più ampia, una migliore capacità di carpire le intenzioni degli utenti e un "quoziente emotivo" (EQ) superiore.
Gli utenti ChatGPT Pro possono selezionare GPT-4.5 dal menù a tendina sulle versioni web, mobile e desktop di Chat GPT. OpenAI prevede di estendere l'accesso agli utenti Plus e Team nelle prossime settimane, seguiti successivamente dagli utenti Enterprise ed Edu.
GPT-4.5 ha accesso ad internet, supporta il caricamento di file e immagini e può lavorare su scrittura e codice. Tuttavia, attualmente non supporta le funzionalità multimodali (Voice Mode, video e condivisione dello schermo).
Apprendimento non supervisionato vs Ragionamento
Lo sviluppo dell'AI avviene attraverso due paradigmi complementari:
- Scaling del ragionamento: insegna ai modelli a "pensare" e generare una catena di pensiero prima di rispondere, permettendo loro di affrontare problemi complessi (o1, o3-mini, DeepSeek R1, l'italiano Vitruvian, l'ibrido Claude 3.7 sono tutti esempi recenti).
- Apprendimento non supervisionato: aumenta l'accuratezza del modello (meno allucinazioni), l'intuizione e la conoscenza generale del mondo.
GPT-4.5 è stato sviluppato seguendo il secondo approccio e l'addestramento è avvenuto sui supercomputer di Microsoft Azure. Rispetto a o1 e o3-mini, GPT-4.5 è un modello più generalista e intrinsecamente più intelligente.
Secondo i test di OpenAI, GPT-4.5 dimostra:
- Un tasso di allucinazione del 37.1%, notevolmente inferiore rispetto al 61.8% di GPT-4o
- Un'accuratezza del 62.5% nel test SimpleQA, superando il 38.2% di GPT-4o
 Fonte: OpenAI
Fonte: OpenAI
"Quoziente Emotivo" (EQ) migliorato
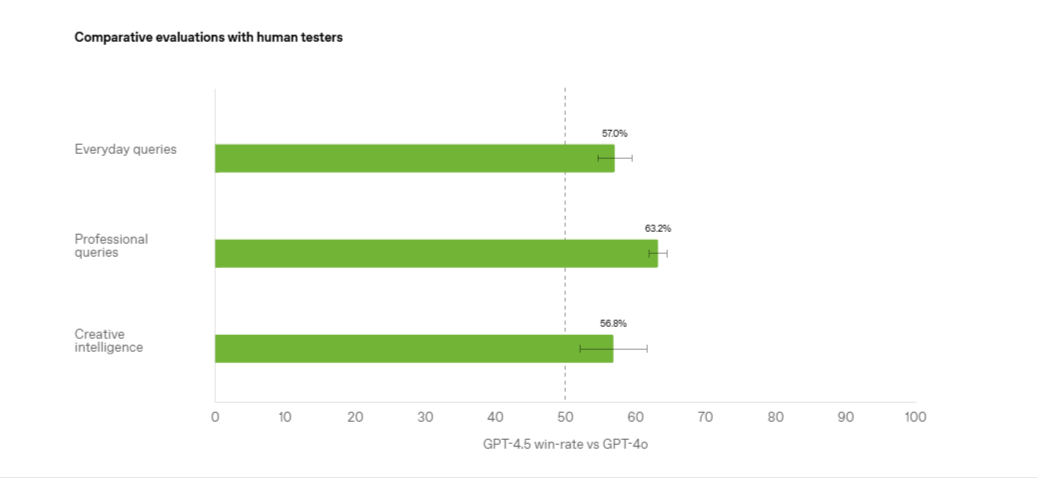
I test condotti da OpenAI mostrano che GPT-4.5 è stato preferito rispetto a GPT-4o in diverse categorie di query:
- Intelligenza creativa: 56.8% di preferenza
- Query professionali: 63.2% di preferenza
- Query quotidiane: 57.0% di preferenza
 Fonte: OpenAI
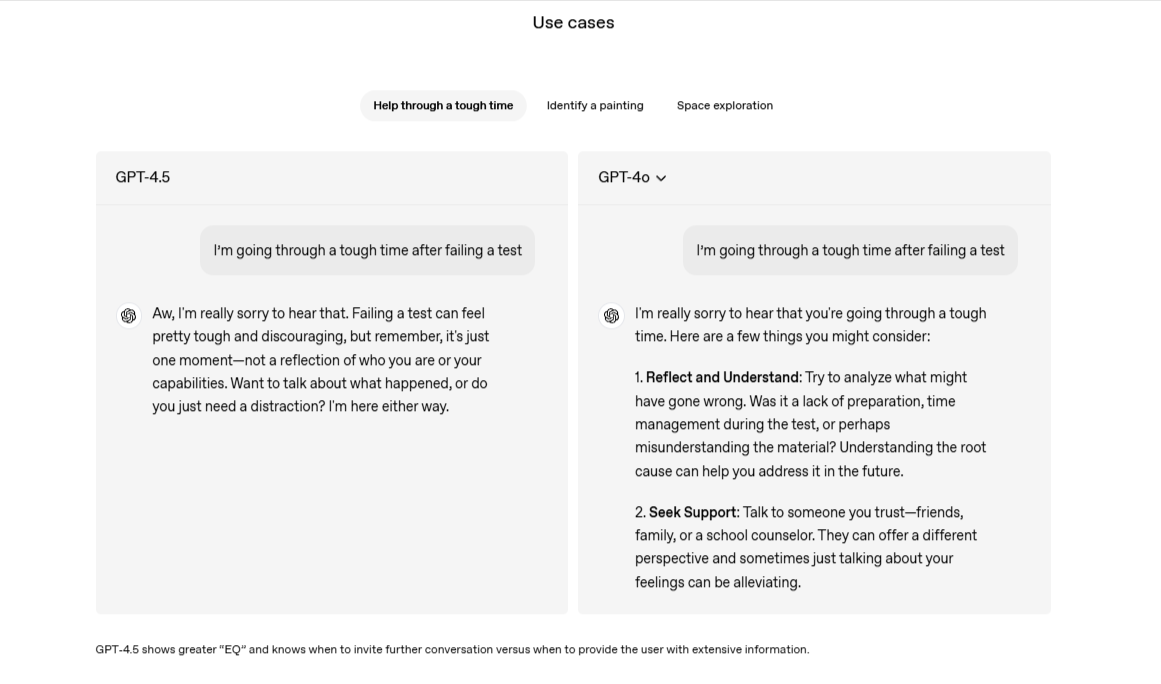
Fonte: OpenAIIn particolare, GPT 4.5 sembra rispondere con più tatto e sensibilità rispetto ai predecessori. Inoltre è più intuitivo, succinto e interessante nelle conversazioni. Si veda la conversazione riportata nella sezione "use cases" dell'articolo di OpenAI:
 Fonte: OpenAI
Fonte: OpenAISicurezza e test
Secondo OpenAI, GPT-4.5 è stato addestrato con nuove tecniche di supervisione combinate con metodi tradizionali di fine-tuning supervisionato (SFT) e apprendimento per rinforzo da feedback umano (RLHF) come quelli utilizzati per GPT-4o.
Prima della distribuzione, OpenAI ha condotto una serie di test di sicurezza in conformità con il loro Preparedness Framework. I risultati dettagliati di queste valutazioni sono pubblicati nella scheda di sistema che accompagna il rilascio.
Il grande problema dei costi
Vale la pena notare che GPT-4.5 è un modello molto grande e computazionalmente impegnativo, il che lo rende più costoso e non un sostituto di GPT-4o. Con un prezzo di $75 per milione di token in input e $150 per milione di token in output, il costo di utilizzo è tra 10 e 25 volte superiore ai competitor. Ciò rende il modello decisamente poco accessibile. Per questo motivo, OpenAI sta valutando se continuare a offrirlo nell'API a lungo termine mentre bilancia il supporto alle capacità attuali con lo sviluppo di modelli futuri.
Le reazioni degli esperti
Le opinioni sul nuovo modello sono state prevedibilmente divise. Da un lato, alcuni esperti hanno lodato le qualità "umane" del modello:
- Sam Altman, CEO di OpenAI, ha definito GPT-4.5 "il primo modello che sembra parlare con una persona riflessiva".
- Ben Hylak lo ha descritto come "il momento Midjourney per la scrittura".
- Dan Shipper (di Every) l'ha trovato "più estroverso e meno nevrotico", sebbene ancora soggetto ad allucinazioni.
- Ethan Mollick ha notato che "può scrivere magnificamente" ma diventa "stranamente pigro su progetti complessi".
Dall'altro lato, non sono mancate critiche:
- Gary Marcus, ricercatore di IA noto per le sue critiche alla corsa all'intelligenza artificiale, l'ha definito un "nothing burger release" (un rilascio inconsistente).
- Lo stesso Altman ha ammesso che si tratta di "un modello gigantesco e costoso" che "non batterà i benchmark".
- Andrej Karpathy, ex ricercatore di OpenAI, ha spiegato che ha richiesto 10 volte più potenza di calcolo per miglioramenti "diffusi" e difficili da percepire.
Prestazioni su benchmark accademici
OpenAI ha fornito i risultati di GPT-4.5 su benchmark accademici standard per illustrare le sue prestazioni attuali su compiti tradizionalmente associati al ragionamento. Anche scalando semplicemente l'apprendimento non supervisionato, GPT-4.5 mostra miglioramenti significativi rispetto a modelli precedenti come GPT-4o.
Ecco alcuni dei risultati più rilevanti:
- GPQA (scienza): 71.4% (GPT-4.5) vs 53.6% (GPT-4o) vs 79.7% (OpenAI o3-mini)
- AIME '24 (matematica): 36.7% (GPT-4.5) vs 9.3% (GPT-4o) vs 87.3% (OpenAI o3-mini)
- MMMLU (multilingue): 85.1% (GPT-4.5) vs 81.5% (GPT-4o) vs 81.1% (OpenAI o3-mini)
- MMMU (multimodale): 74.4% (GPT-4.5) vs 69.1% (GPT-4o)
Fonte: OpenAI
